#Apache Spark Renjin Executor (REX)
REX is an Apache Spark package offering access to the scientific computing power of the R programming language to Spark batch and streaming applications on the JVM. This library is built on top of the renjin-r-executor library, a lightweight solution for integrating R analytics executed on the Renjin R interpreter into any application running on the JVM.
IMPORTANT: The Renjin R interpreter for statistical computing is currently a work-in-progress and is not yet 100% compatible with GNU R. To find which CRAN R packages are currently supported by Renjin you can browse or search the Renjin package repository. As Renjin compatibility with GNU R continues to improve, REX is ready to deliver those improvements directly to Apache Spark batch and streaming applications on the JVM. If Renjin does not meet your needs today then I recommend checking out ROSE, an alternative library that today offers access to the full scientific computing power of the R programming language to Apache Spark applications.
Where Apache SparkR lets data scientists use Spark from R, REX is designed to let Scala and Java developers use R from Spark.
The popular Apache SparkR package provides a lightweight front-end for data scientists to use Apache Spark from R. This approach is ideally suited to investigative analytics, such as ad-hoc and exploratory analysis at scale.
The REX library attempts to provide the same R analytics capabilities
available to Apache SparkR applications within traditional Spark applications
on the JVM. It does this by exposing new analyze operations that execute R
analytics on compatible RDDs. This new facility is designed primarily for
operational analytics and can be used alongside Spark core, SQL, Streaming,
MLib and GraphX.
If you need to query R machine-learning models, score R prediction models or leverage any other aspect of the R library within your Spark applications on the JVM then the REX library may be for you.
A number of example applications are provided to demonstrate the use of the REX library to deliver R analytics capabilities within any Spark solution.
libraryDependencies += "io.onetapbeyond" %% "renjin-spark-executor_2.10" % "1.0"
compile 'io.onetapbeyond:renjin-spark-executor_2.10:1.0'
Include the REX package in your Spark application using spark-shell, or spark-submit. For example:
$SPARK_HOME/bin/spark-shell --packages io.onetapbeyond:renjin-spark-executor_2.10:1.0
This library exposes new analyze transformations on Spark RDDs of type
RDD[RenjinTask]. The following sections demonstrate how to use these new
RDD operations to execute R analytics directly within Spark batch and
streaming applications on the JVM.
See the documentation
on the underlying renjin-r-executor library for details on building
RenjinTask and handling RenjinResult.
For this example we assume an input dataRDD, then transform it to generate
an RDD of type RDD[RenjinTask]. In this example each RenjinTask will
execute a block of task specific R code when the RDD is eventually evaluated.
import io.onetapbeyond.renjin.spark.executor.R._
import io.onetapbeyond.renjin.r.executor._
val rTaskRDD = dataRDD.map(data => {
Renjin.R()
.code(rCode)
.input(data.asInput())
.build()
})
The set of RenjinTask within rTaskRDD can be scheduled for
processing by calling the new analyze operation provided by REX
on the RDD:
val rResultRDD = rTaskRDD.analyze
When rTaskRDD.analyze is evaluated by Spark the resultant rResultRDD
is of type RDD[RenjinResult]. The result returned by the block of the
task specific R code for the original RenjinTask is available
within these RenjinResult. These values can be optionally cached, further
processed or persisted per the needs of your Spark application.
Note, the block of task specific R code can make use of any CRAN R package function or script that is supported by the Renjin R interpreter. To find which CRAN R packages are currently supported by Renjin you can browse or search the Renjin package repository.
For this example we assume an input stream dataStream, then transform
it to generate a new stream with underlying RDDs of type RDD[RenjinTask].
In this example each RenjinTask will execute a block of task specific R
code when the stream is eventually evaluated.
import io.onetapbeyond.renjin.spark.executor.R._
import io.onetapbeyond.renjin.r.executor._
val rTaskStream = dataStream.transform(rdd => {
rdd.map(data => {
Renjin.R()
.code(rCode)
.input(data.asInput())
.build()
})
})
The set of RenjinTask within rTaskStream can be scheduled for processing
by calling the new analyze operation provided by REX on each RDD within
the stream:
val rResultStream = rTaskStream.transform(rdd => rdd.analyze)
When rTaskStream.transform is evaluated by Spark the resultant
rResultStream has underlying RDDs of type RDD[RenjinResult]. The result
returned by the block of task specific R code for the original
RenjinTask is available within these RenjinResult. These values can
be optionally cached, further processed or persisted per the needs of your
Spark application.
Note, the block of task specific R code can make use of any CRAN R package function or script that is supported by the Renjin R interpreter. To find which CRAN R packages are currently supported by Renjin you can browse or search the Renjin package repository.
To understand how REX delivers the scientific computing power of the R programming language to Spark applications on the JVM the following sections compare and constrast the deployment of traditional Scala, Java, Python and SparkR applications with Spark applications powered by the REX library.
The sole deployment requirement when working with the REX library is to
add the necessary Java Archive (.jar) dependencies to your Spark application
for REX, for the Renjin interpreter itself and for any
Renjin-compatible CRAN R packages that
your R code will use. This is discussed in
greater detail in Application Deployment section 3. that follows below.
####1. Traditional Scala | Java | Python Spark Application Deployment
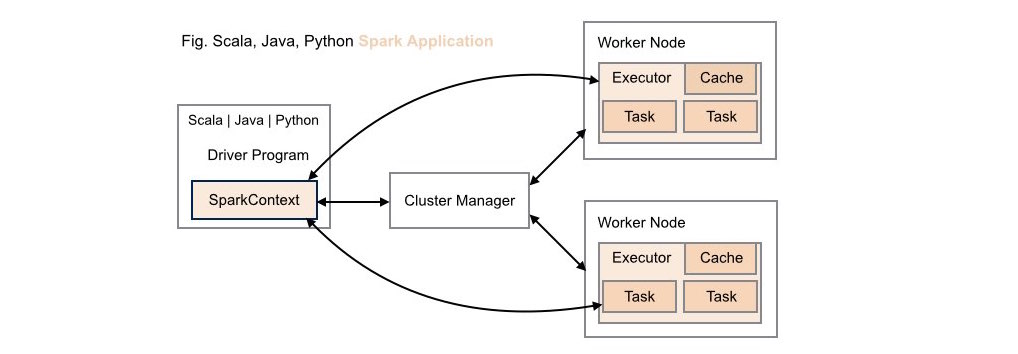
Without REX library support, neither data scientists nor application developers have access to R's analytic capabilities within these types of application deployments.
####2. Traditional SparkR Application Deployment
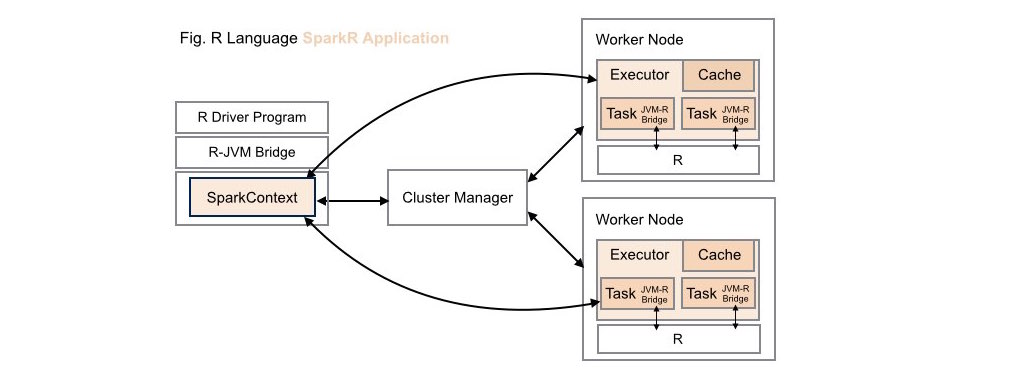
While data scientists can leverage the computing power of Spark within R applications in these types of application deployments, these same R capabilities are not available to Scala, Java or Python developers.
Note, when working with Apache SparkR, the R runtime environment must be installed locally on each worker node on your cluster.
####3. Scala | Java + R (REX) Spark Application Deployment
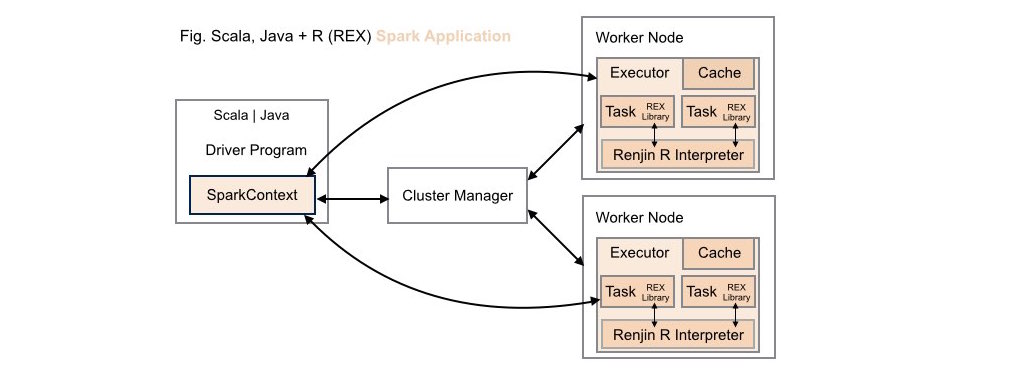
Both data scientists and application developers working in either Scala or Java can leverage the power of R using the REX library within these types of application deployments.
As REX, the Renjin R interpreter and all
Renjin-compatible CRAN R packages all
native JVM libraries these dependencies are made available as standard
JAR artifacts available for download or inclusion as managed
dependencies from a Maven repository.
For example, the basic Maven artifact dependency delcarations for a
REX-powered Spark batch application using the sbt build tool look
as follows:
libraryDependencies ++= Seq(
"org.apache.spark" % "spark-core_2.10" % "version" % "provided",
"io.onetapbeyond" % "renjin-spark-executor" % "version",
"org.renjin" % "renjin-script-engine" % "version"
)
As a further example, the Maven artifact dependencies for a REX-powered
Spark streaming application that depends on the Renjin-compatible CRAN
R survey package using the sbt build tool look as follows:
libraryDependencies ++= Seq(
"org.apache.spark" % "spark-streaming_2.10" % "version" % "provided",
"io.onetapbeyond" % "renjin-spark-executor" % "version",
"org.renjin" % "renjin-script-engine" % "version",
"org.renjin.cran" % "survey" % "version"
)
All Renjin artifacts are maintained within a Maven repository
managed by BeDataDriven, the creators
of the Renjin interpreter. To use these artifacts you must identify
the BeDataDriven Maven repository to your build tool. For example,
when using sbt the required resolver is as follows:
resolvers +=
"BeDataDriven" at "https://nexus.bedatadriven.com/content/groups/public"
Note, as REX is powered by Renjin there is no need to install the R runtime environment locally on each worker node on your cluster. This means REX works out-of-the box with all new or existing Spark clusters.
See the LICENSE file for license rights and limitations (Apache License 2.0).