

Kraps-rpc is a RPC framework split from Spark, you can regard it as spark-rpc with the word spark reversed.
This module is mainly for studying how RPC works in Spark, as people knows that Spark consists many distributed components, such as driver, master, executor, block manager, etc, and they communicate with each other through RPC. In Spark project the functionality is sealed in Spark-core module. Kraps-rpc separates the core RCP part from it, not including security and streaming download feature.
The module is based on Spark 2.1 version, which eliminate Akka due to SPARK-5293.
- 0. Dependency
- 1. How to run
- 2. About RpcConf
- 3. More examples
- 4. Performance test
- 5. Dependency tree
You can configure you project by including dependency from below, currently only work with scala 2.11.
Maven:
<dependency>
<groupId>net.neoremind</groupId>
<artifactId>kraps-rpc_2.11</artifactId>
<version>1.0.0</version>
</dependency>
SBT:
"net.neoremind" % "kraps-rpc_2.11" % "1.0.0"
To learn more dependencies, please go to Dependency tree section.
The following examples can be found in kraps-rpc-example
Creating an endpoint which contains the business logic you would like to provide as a RPC service. Below shows a simple example of a hello world echo service.
class HelloEndpoint(override val rpcEnv: RpcEnv) extends RpcEndpoint {
override def onStart(): Unit = {
println("start hello endpoint")
}
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case SayHi(msg) => {
println(s"receive $msg")
context.reply(s"hi, $msg")
}
case SayBye(msg) => {
println(s"receive $msg")
context.reply(s"bye, $msg")
}
}
override def onStop(): Unit = {
println("stop hello endpoint")
}
}
case class SayHi(msg: String)
case class SayBye(msg: String)
RpcEndpoint is where to receive and handle requests, as actor notation in akka. RpcEndpoint does differentiate message need-not-reply from need-reply. Former one is much like UDP message (send and forget), latter one follows tcp way, waiting for one response.
/**
* Process messages from [[RpcEndpointRef.send]] or [[RpcCallContext.reply)]]. If receiving a
* unmatched message, [[SparkException]] will be thrown and sent to `onError`.
*/
def receive: PartialFunction[Any, Unit] = {
case _ => throw new SparkException(self + " does not implement 'receive'")
}
/**
* Process messages from [[RpcEndpointRef.ask]]. If receiving a unmatched message,
* [[SparkException]] will be thrown and sent to `onError`.
*/
def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
case _ => context.sendFailure(new SparkException(self + " won't reply anything"))
}
One RpcCallContext is provided for endpoint to separate endpoing logic from message network transport process. Providing function to reply result or send failure information:
- reply(response: Any) : reply one message
- sendFailure(e: Throwable) : send failure
Also a serious status callbacks are provided :
- onError
- onConnected
- onDisconnected
- onNetworkError
- onStart
- onStop
- stop
There are a couple of steps to create a RPC server which provide HelloEndpoint service.
- Create
RpcEnvServerConfig,RpcConfis where you can specify some parameters for the server, will be discussed in the below section,hello-serveris just a simple name, no real use later. Host and port must be specified. Note that if server cannot bind on the specified port, it will try to increase the port value by one and try next. - Create
RpcEnvwhich launches the server via TCP socket at localhost on port 52345. - Create
HelloEndpointand setup it with an identifier ofhello-service, the name is for client to call and route into the correct service. awaitTerminationwill block the thread and make server run without exiting JVM.
import net.neoremind.kraps.RpcConf
import net.neoremind.kraps.rpc._
import net.neoremind.kraps.rpc.netty.NettyRpcEnvFactory
object HelloworldServer {
def main(args: Array[String]): Unit = {
val config = RpcEnvServerConfig(new RpcConf(), "hello-server", "localhost", 52345)
val rpcEnv: RpcEnv = NettyRpcEnvFactory.create(config)
val helloEndpoint: RpcEndpoint = new HelloEndpoint(rpcEnv)
rpcEnv.setupEndpoint("hello-service", helloEndpoint)
rpcEnv.awaitTermination()
}
}
Creating RpcEnv is the same as above, and here use setupEndpointRef to create a stub to call remote server at localhost on port 52345 and route to hello-service.
Future is used here for asynchronous invocation.
import net.neoremind.kraps.RpcConf
import net.neoremind.kraps.rpc.{RpcAddress, RpcEndpointRef, RpcEnv, RpcEnvClientConfig}
import net.neoremind.kraps.rpc.netty.NettyRpcEnvFactory
import scala.concurrent.{Await, Future}
import scala.concurrent.duration.Duration
import scala.concurrent.ExecutionContext.Implicits.global
object HelloworldClient {
def main(args: Array[String]): Unit = {
import scala.concurrent.ExecutionContext.Implicits.global
val rpcConf = new RpcConf()
val config = RpcEnvClientConfig(rpcConf, "hello-client")
val rpcEnv: RpcEnv = NettyRpcEnvFactory.create(config)
val endPointRef: RpcEndpointRef = rpcEnv.setupEndpointRef(RpcAddress("localhost", 52345), "hell-service")
val future: Future[String] = endPointRef.ask[String](SayHi("neo"))
future.onComplete {
case scala.util.Success(value) => println(s"Got the result = $value")
case scala.util.Failure(e) => println(s"Got error: $e")
}
Await.result(future, Duration.apply("30s"))
}
}
Creating RpcEnv is the same as above, and here use setupEndpointRef to create a stub to call remote server at localhost on port 52345 and route to hello-service.
Use askWithRetry instead of ask to call in synchronous way.
Note that in latest Spark version the method signature has changed to askSync.
object HelloworldClient {
def main(args: Array[String]): Unit = {
import scala.concurrent.ExecutionContext.Implicits.global
val rpcConf = new RpcConf()
val rpcConf = new RpcConf()
val config = RpcEnvClientConfig(rpcConf, "hello-client")
val rpcEnv: RpcEnv = NettyRpcEnvFactory.create(config)
val endPointRef: RpcEndpointRef = rpcEnv.setupEndpointRef(RpcAddress("localhost", 52345), "hello-service")
val result = endPointRef.askWithRetry[String](SayBye("neo"))
println(result)
}
}
RpcConf is simply SparkConf in Spark, there are a couple of parameters that can be adjusted. They are listed below, for most of them you can reference to Spark Configuration. For example, you can specify parameter in the following way.
val rpcConf = new RpcConf()
rpcConf.set("spark.rpc.lookupTimeout", "2s")
The parameters can also be set in VM options like:
-Dspark.rpc.netty.dispatcher.numThreads=16 -Dspark.rpc.io.threads=8
| Configuration | Description |
|---|---|
| spark.rpc.lookupTimeout | Timeout to use for RPC remote endpoint lookup, whenever a call is made the client will always ask the server whether specific endpoint exists or not, this is for the asking timeout, default is 120s |
| spark.rpc.askTimeout | Timeout to use for RPC ask operations, default is 120s |
| spark.rpc.numRetries | Number of times to retry connecting, default is 3 |
| spark.rpc.retry.wait | Number of milliseconds to wait on each retry, default is 3s |
| spark.rpc.io.numConnectionsPerPeer | Spark RPC maintains an array of clients and randomly picks one to use. Number of concurrent connections between two nodes for fetching data. For reusing, used on client side to build client pool, please always set to 1, default is 1. |
| spark.rpc.netty.dispatcher.numThreads | For server side, actor Inbox dispatcher thread pool size, it is where endpoint business logic runs, if endpoints stall and reach to this number, event new RPC messages can be accepted, but server can not handle them in endpoint due to the limit, default is 8. |
| spark.rpc.io.threads | For server and client side netty eventloop, this number is reactor thread pool size, the thread is responsible for accepting new connections and closing connections, serialize and deserialize byte array to RpcMessage object and push RpcMessage to actor pattern based Inbox for dispatcher to pick up and process, dispatcher concurrent level is set byspark.rpc.netty.dispatcher.numThreads. Default number is CPU cores * 2, min is 1. |
Please find more in test cases.
One server and one client will be setup for testing at the same rack hosted in VM in different phasical machines. Test environment lists as below.
CPU: Intel(R) Xeon(R) CPU E5-2620 v3 @ 2.40GHz 4 cores
Memory: 8G
OS: Linux ap-inf01 4.4.0-78-generic #99-Ubuntu SMP Thu Apr 27 15:29:09 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
JDK:
OpenJDK Runtime Environment (build 1.8.0_131-8u131-b11-2ubuntu1.16.04.3-b11)
OpenJDK 64-Bit Server VM (build 25.131-b11, mixed mode)
All performance related test cases can be found in kraps-rpc-example. Keep all parameters as default values.
Click here to see server test case. Server running command is
java -server -Xms4096m -Xmx4096m -cp kraps-rpc-example_2.11-1.0.1-SNAPSHOT-jar-with-dependencies.jar HelloworldServer <ip>
Click here to see client test case. Client running command is
java -server -Xms2048m -Xmx2048m -cp kraps-rpc-example_2.11-1.0.1-SNAPSHOT-jar-with-dependencies.jar PerformanceTestClient <ip> <invocation number> <concurrent calls>
Peak QPS will reach to more than 18k as concurrent level goes up.
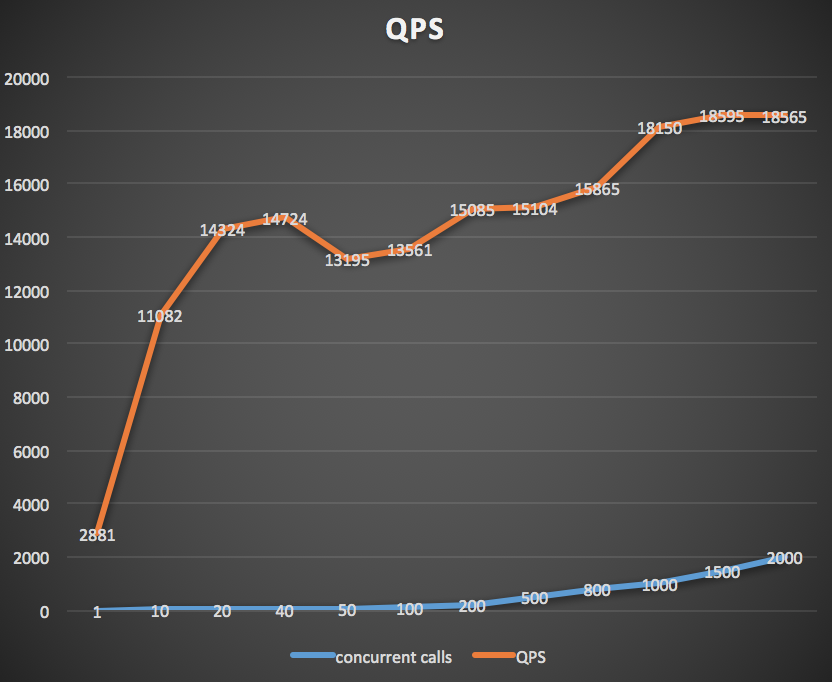
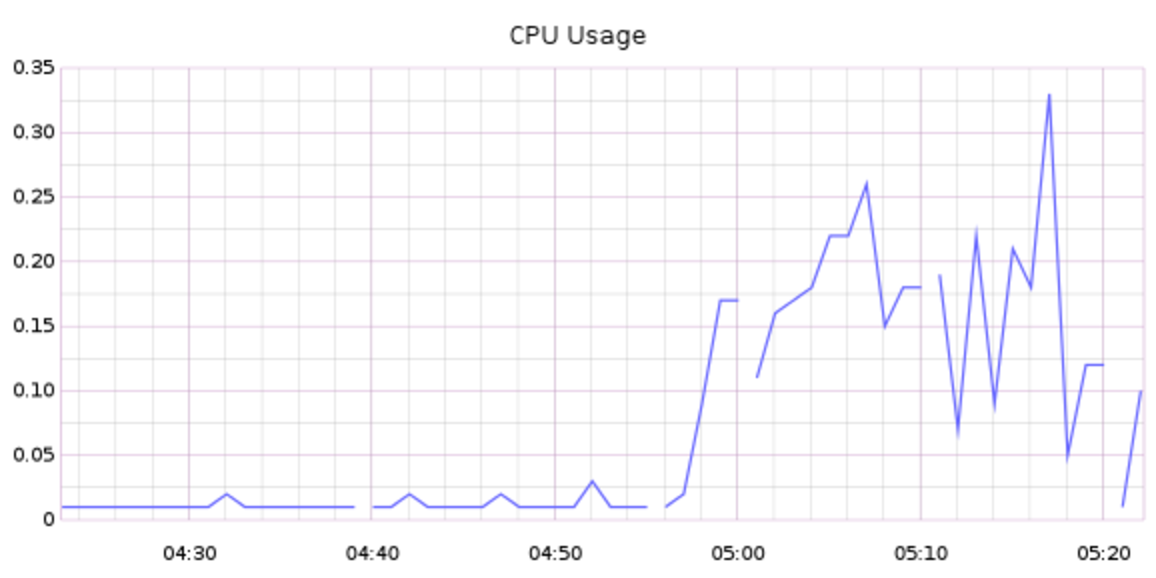
Below is CPU usage of server VM during the time performance tests are executed.
Below is CPU usage of client VM during the time performance tests are executed.

As shown above, during testing phase, server workload is not very high, I think there is still room for higher QPS if more concurrent client calls could be made.
[INFO] +- org.apache.spark:spark-network-common_2.11:jar:2.1.0:compile
[INFO] | +- io.netty:netty-all:jar:4.0.42.Final:compile
[INFO] | +- org.apache.commons:commons-lang3:jar:3.5:compile
[INFO] | +- org.fusesource.leveldbjni:leveldbjni-all:jar:1.8:compile
[INFO] | +- com.fasterxml.jackson.core:jackson-databind:jar:2.6.5:compile
[INFO] | +- com.fasterxml.jackson.core:jackson-annotations:jar:2.6.5:compile
[INFO] | +- com.google.code.findbugs:jsr305:jar:1.3.9:compile
[INFO] | +- org.apache.spark:spark-tags_2.11:jar:2.1.0:compile
[INFO] | \- org.spark-project.spark:unused:jar:1.0.0:compile
[INFO] +- de.ruedigermoeller:fst:jar:2.50:compile
[INFO] | +- com.fasterxml.jackson.core:jackson-core:jar:2.8.8:compile
[INFO] | +- org.javassist:javassist:jar:3.21.0-GA:compile
[INFO] | +- org.objenesis:objenesis:jar:2.5.1:compile
[INFO] | \- com.cedarsoftware:java-util:jar:1.9.0:compile
[INFO] | +- commons-logging:commons-logging:jar:1.1.1:compile
[INFO] | \- com.cedarsoftware:json-io:jar:2.5.1:compile
[INFO] +- org.scala-lang:scala-library:jar:2.11.8:compile
[INFO] +- org.slf4j:slf4j-api:jar:1.7.7:compile
[INFO] +- org.slf4j:slf4j-log4j12:jar:1.7.7:compile
[INFO] | \- log4j:log4j:jar:1.2.17:compile
[INFO] +- com.google.guava:guava:jar:15.0:compile
The development of Kraps-rpc is inspired by Spark. Kraps-rpc with Apache2.0 Open Source License retains all copyright, trademark, author’s information from Spark.