



A package for dealing with crowdsourced big data.
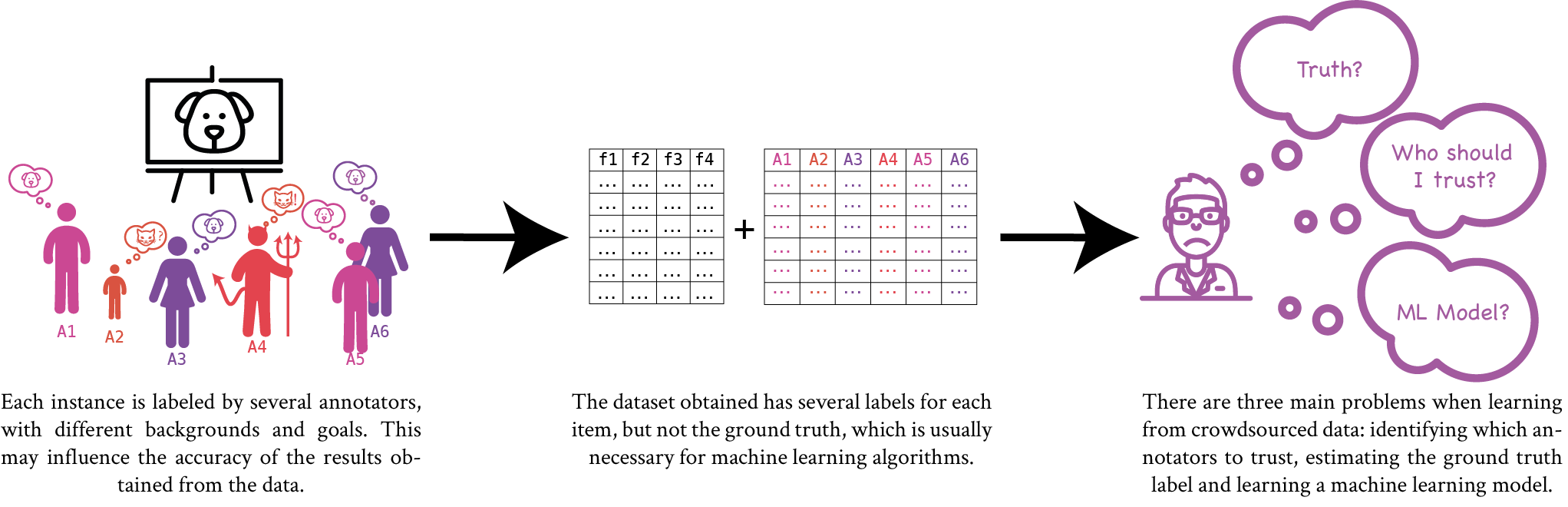
Crowdsourced data introduces new problems that need to be addressed by Machine learning algorithms. This illustration exemplifies the main issues of using this kind of data.
The package uses sbt for building the project, so we recommend installing this tool if you do not yet have it installed.
The simplest way to use the package is adding the next dependency directly
into the build.sbt file of your project.
libraryDependencies += "com.enriquegrodrigo" %% "spark-crowd" % "0.2.1"If this is not a possibility, you can compile the project and create a
.jar file or, you can publish the project to a local repository, as
explained below.
In the spark-crowd folder, one should execute the command
> sbt package
to create a .jar file. Usually, it is located in
target/scala-2.11/spark-crowd_2.11-0.2.1.jar.
This .jar can be added to new projects using this library. In sbt one
can add .jar files to the lib folder.
In the spark-crowd folder, one should execute the command
> sbt publish-local
to publish the library to a local Ivy repository. The
library can be added to the build.sbt file of a new
project with the following line:
libraryDependencies += "com.enriquegrodrigo" %% "spark-crowd" % "0.2.1"

For running the examples of this package one can use our docker image with the latest version of spark-crowd. Let's see how to run the DawidSkeneExample.scala file:
docker run --rm -it -v $(pwd)/:/home/work/project enriquegrodrigo/spark-crowd DawidSkeneExample.scala
For running a spark-shell with the library pre-loaded, one can use:
docker run --rm -it -v $(pwd)/:/home/work/project enriquegrodrigo/spark-crowd
One can also generate a .jar file as seen previously and use it with spark-shell or spark-submit. For example, with spark-shell:
spark-shell --jars spark-crowd_2.11-0.2.1.jar -i DawidSkeneExample.scala
This package makes extensive use of Spark DataFrame and Dataset APIs. The latter takes advantage of typed rows which is beneficial for debugging purposes, among other things. As the annotations data sets usually have a fixed structure the package includes types three annotations data sets (binary, multiclass and real annotations), all of them with the following structure:
| example | annotator | value |
|---|---|---|
| 1 | 1 | 0 |
| 1 | 2 | 1 |
| 2 | 2 | 0 |
| ... | ... | ... |
So the user needs to provide the annotations using this typed data sets to apply the learning methods. This is usually simple if the user has all the information above in a Spark DataFrame:
- The
examplevariable should be in the range[0..number of Examples] - The
annotatorvariable should be in the range[0..number of Annotators] - The
valuevariable should be in the range[0..number of Classes]
import com.enriquegrodrigo.spark.crowd.types.BinaryAnnotation
val df = annotationDataFrame
val converted = df.map(x => BinaryAnnotation(x.getLong(0), x.getLong(1), x.getInt(2)))
.as[BinaryAnnotation]The process is similar for the other types of annotation data. The converted Spark Dataset is ready to be use with the methods commented in the Methods subsection.
In the case of the feature dataset, the requisites are that:
- Appart from the features, the data must have an
exampleand aclasscolumns. - The example must be of type
Long. - Class must be of type
IntegerorDouble, depending on the type of class (discrete or continuous). - All features must be of type
Double. For discrete features one can use indicator variables.
The methods implemented as well as the type of annotations that they support are summarised in the following table:
| Method | Binary | Multiclass | Real | Reference |
|---|---|---|---|---|
| MajorityVoting | ✅ | ✅ | ✅ | |
| DawidSkene | ✅ | ✅ | JRSS | |
| IBCC | ✅ | ✅ | AISTATS | |
| GLAD | ✅ | NIPS | ||
| CGLAD | ✅ | IDEAL | ||
| Raykar | ✅ | ✅ | ✅ | JMLR |
| CATD | ✅ | VLDB | ||
| PM | ✅ | SIGMOD | ||
| PMTI | ✅ | VLDB2 |
The algorithm name links to the documentation of the implemented method in our application. The
Reference column contains a link to where the algorithm was published. As an example, the
following code shows how to use the DawidSkene method:
import com.enriquegrodrigo.spark.crowd.methods.DawidSkene
//Dataset of annotations
val df = annotationDataset.as[MulticlassAnnotation]
//Parameters for the method
val eMIters = 10
val eMThreshold = 0.01
//Algorithm execution
result = DawidSkene(df,eMIters, eMThreshold)
annotatorReliability = result.params.pi
groundTruth = result.datasetThe information obtained from each algorithm as well as about the parameters needed by them can be found in the documentation.
Author:
- Enrique G. Rodrigo
Contributors:
- Juan A. Aledo
- Jose A. Gamez
MIT License
Copyright (c) 2017 Enrique González Rodrigo
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.